












Try Document Filters
Get a functional 21-day trial copy of the solution to get a feel of what it can do for your organization.

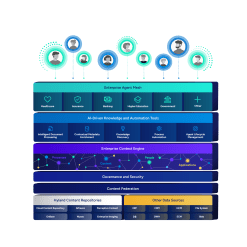
From identification to output, Document Filters is a document processing engine that unlocks the power of unstructured content — giving AI agents the context they need to deliver smarter, more accurate results.
Identify and extract every document, email, archive and container format while analyzing all text and data associated with your content.
Seamlessly manipulate and render high-definition content in a web-safe format with tools to apply precise redaction marks, annotations and more.
Export content and easily convert it for use in other locations. Replicate original files and combine pages from different documents to create packets.
Deploy across 31 software platforms and architectures, and work with nearly any programming language to identify more than 600 file formats.
Check out these demos to see how Document Filters identifies, inspects, extracts, manipulates and converts files.

File formats supported

File formats supported for high-definition rendering

Platforms and architectures the SDK is built on

Get a functional 21-day trial copy of the solution to get a feel of what it can do for your organization.