








Benefits
Ease the burden of bringing valuable new information into the enterprise with intelligently automated capture tools.
Automate the intake of information like emails, invoices, transcripts and more into business systems, and kick-off processes with accurate, up-to-date data.

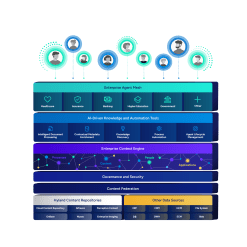
Quick and accurate content onboarding is a critical prerequisite to many vital business processes. Built on an AI-native architecture, Hyland’s document processing technology significantly boosts process efficiency and performance.
LLM-based recognition engines accurately identify information in scanned documents including printed text, handwriting and other elements like checkboxes, signatures and stamps.
Scanned or imported documents are automatically categorized by document types, and packets of multiple documents are automatically separated into individual documents for further processing.
Business-critical data is extracted from the document, validated to be in the correct format, and if needed, verified against systems of record.
Applying gen AI to the intake process can provide new insights, such as autogenerated document summaries, analyses and informed predictions.
Extracted or imported data is automatically sent to the relevant systems and workflows, freeing staff from manual copying and pasting.
Web-based interface with low-code design studio makes automation design, deployment and management easy and accessible.
— Ninja Kobor, Solution Owner, Siemens

Explore expert coverage of Hyland from the world’s most trusted and respected analyst firms.

Gain a decisive advantage in the rapidly evolving IDP market. See why IDC MarketScape named Hyland a Leader in its latest assessment.

Automation can make a major positive impact for an organization. Explore how the automation landscape is shaping up as AI and more connective content management products evolve.

Review new data from industry analyst and Intelligent Business Strategies CEO Mike Ferguson about how AI and content intelligence can maximize your business value.
