
Was ist Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) ist eine KI-Methode, die die Sprachverständnisfähigkeiten großer Sprachmodelle (LLMs) mit der Echtzeitabfrage externer Daten kombiniert. Dieser Ansatz verbessert die Genauigkeit, Relevanz und das Kontextverständnis von KI-generierten Antworten, indem er sie in aktualisierte, autoritative Wissensquellen einbettet.

Whitepaper: Maximieren Sie Ihren Geschäftswert mit Content Intelligence und KI
Das Analystenunternehmen Intelligent Business Strategies untersucht, wie Hyland Ihnen hilft, den verborgenen Wert Ihrer Daten zu erschließen
Sie können die Herausforderungen bei der Verwaltung unstrukturierter Daten meistern und diese mit KI in verwertbare Erkenntnisse umwandeln. Lesen Sie dieses bahnbrechende Whitepaper der Analystenfirma Intelligent Business Solutions, um die neuesten Innovationen im Content-Management zu erkunden. Laden Sie jetzt Ihr Exemplar herunter und machen Sie mit Hyland den ersten Schritt, um fragmentierte Daten in einen strategischen Vorteil zu verwandeln.
Der Unterschied zwischen RAG und traditionellen LLMs
Traditionelle LLMs verlassen sich ausschließlich auf ihre statischen Trainingsdaten, was zu veralteten oder ungenauen Ausgaben führen kann. RAG behebt diese Einschränkung, indem es dynamisch relevante Informationen aus externen Wissensdatenbanken abruft und so sicherstellt, dass die Antworten konsistent, fundiert und vertrauenswürdig sind. Die RAG wurde entwickelt, um den Anforderungen moderner Unternehmen gerecht zu werden und KI zu nutzen, um zuverlässigere Geschäftsergebnisse zu liefern.
So funktioniert RAG
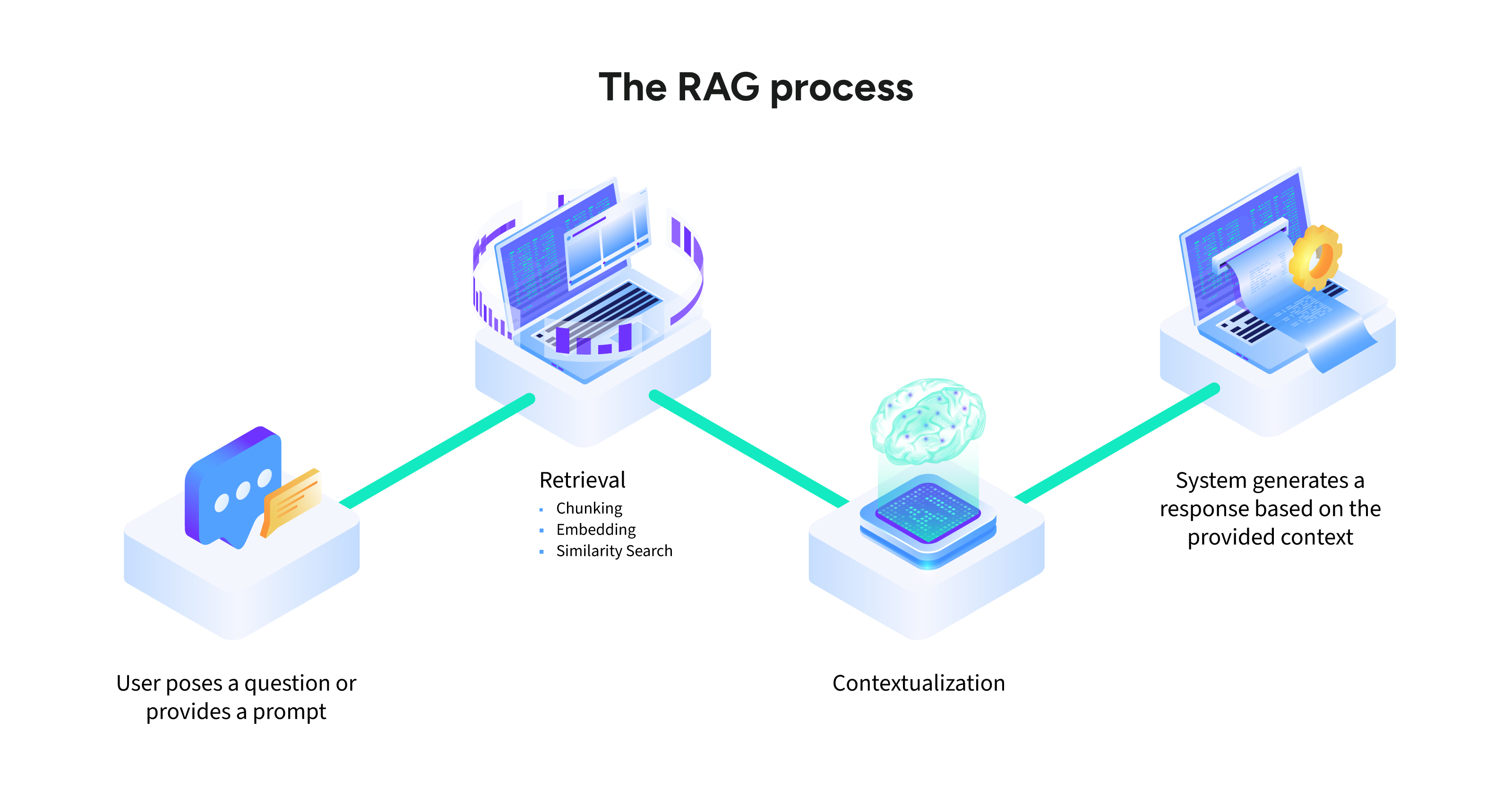
RAG arbeitet mit einem gut strukturierten Prozess, der sicherstellt, dass generative Modelle detaillierte, präzise und fundierte Antworten liefern. Im Folgenden sind die wichtigsten Schritte im RAG-Framework aufgeführt:
Abfrageverarbeitung
Der Prozess beginnt, wenn ein Benutzer eine Suchabfrage oder Eingabe sendet. Diese Eingabe wird analysiert und in eine maschinenlesbare Einbettung umgewandelt, die eine numerische Darstellung des Textes darstellt.
Informationsabruf
Das System identifiziert und sucht relevante Informationen aus externen Quellen wie Datenbanken, APIs oder Dokumentenspeichern ab. Dieser Schritt umfasst:
Chunking: Das Aufteilen großer Dokumente in kleinere, handlichere Abschnitte.
Embedding-Abgleich: Die Umwandlung von Textabschnitten in numerische Einbettungen zum Abgleich mit der Suchabfrage.
Relevanzbewertung: Die Verwendung von Algorithmen wie der semantischen Suche, um die kontextuell relevantesten Daten zu priorisieren.
Kontextualisierung
Relevante Daten, die aus externen Quellen gesucht werden, werden an die ursprüngliche Suchabfrage angehängt, um eine umfassende, erweiterte Eingabeaufforderung zu erstellen. Dies stellt sicher, dass das LLM über genügend Kontext verfügt, um seine Antwort zu generieren.
Antwortgenerierung
Das LLM verarbeitet die angereicherte Eingabeaufforderung, um eine Antwort zu generieren, die sowohl die gesuchten Daten als auch sein vortrainiertes Wissen enthält. Dieser ausgewogene Ansatz stellt sicher, dass die Ausgaben spezifisch, genau und relevant sind.
Endausgabe
Die Antwort wird dem Benutzer präsentiert, häufig mit Verweisen oder Links zu den verwendeten Quellen. Diese Transparenz schafft Vertrauen und bietet den Nutzern tiefere Einblicke.
Werkzeuge und Technologien hinter RAG
Der Aufbau eines robusten RAG-Systems erfordert fortschrittliche Werkzeuge und Technologien, die Folgendes umfassen:
Vektordatenbanken: Plattformen wie Hyland Content Innovation Cloud™, die Suchdaten basierend auf semantischer Ähnlichkeit unterstützen und den Abrufprozess beschleunigen.
Dense Retrieval-Modelle: Fortgeschrittene Abrufalgorithmen, wie das Dense Passage Retrieval (DPR), identifizieren die relevantesten Informationen für eine bestimmte Suchabfrage.
Entwicklungsframeworks: Open-Source-Frameworks wie LangChain vereinfachen die Integration von LLMs, Abrufsystemen und Einbettungsmodellen für RAG-gestützte Anwendungen.
Hardware-Optimierung: Wenn Sie On-Premise RAG nutzen möchten, benötigen Sie Hochleistungshardware, wie z. B. die KI-beschleunigten Chips von NVIDIA, die eine effiziente und großflächige Verarbeitung in RAG-Systemen gewährleisten. Alternativ könnten Sie einen LLM-Anbieter nutzen, in welchem Fall es möglich ist, dass nur sehr wenig oder gar keine Hardware erforderlich wäre.
Diese Tools ermöglichen es Unternehmen, skalierbare Lösungen zu implementieren, die kontextbezogene Ergebnisse in Echtzeit liefern.

Der Aufstieg der Content Intelligence: Eine neue Ära der Innovation im ECM
In einer kürzlich von Forrester Consulting durchgeführten und von Hyland in Auftrag gegebenen Umfrage präsentierte Forrester Ergebnisse, die die Bedeutung der Nutzung der Macht von Unternehmensinhalten und unstrukturierten Daten hervorheben.
Erfahren Sie mehr über die Ergebnisse der Studie und darüber, welche Content-Intelligence-Funktionen erfolgversprechend sind.
Die Vorteile von RAG
RAG bietet mehrere Vorteile, die seine Effektivität für Unternehmen und Betriebe gleichermaßen erhöhen:
Verbesserte Genauigkeit
Die Verankerung von LLM-Antworten in geprüften externen Wissensquellen gewährleistet ein höheres Maß an faktischer Konsistenz und verringert Fehlinformationen.
Echtzeitrelevanz
RAG ermöglicht den Zugriff auf aktuelle, reale Informationen und vermeidet die Stagnation, die bei veralteten LLM-Trainingsdaten auftritt.
Kosteneffizienz
Im Gegensatz zu herkömmlichen Retraining-Prozessen für KI-Modelle bezieht RAG aktualisierte und relevante Informationen dynamisch ein, ohne dass kostspielige Feinabstimmungen erforderlich sind.
Domänenspezifische Genauigkeit
RAG unterstützt maßgeschneiderte Integrationen mit branchenspezifischen Wissensdatenbanken und ermöglicht präzise und zuverlässige Ausgaben, die auf Nischenbereiche wie das Gesundheits-, Finanz- und Rechtswesen zugeschnitten sind. Einer der Hauptvorteile von RAG gegenüber LLMs ist die Fähigkeit, Wissen aus privaten Repositorys abzurufen, auf die LLMs nicht trainiert sind. Dies ermöglicht eine größere Genauigkeit in seinen Antworten.
Reale Anwendungen von RAG
Die Anpassungsfähigkeit von RAG macht es in verschiedenen Branchen und Anwendungsfällen äußerst wertvoll. Hier sind einige Beispiele:
Kundensupport
RAG-basierte KI-Chatbots liefern hochgradig personalisierte Antworten, indem sie interne Richtlinien, FAQs und fallspezifische Daten nutzen. Sie minimieren Wartezeiten und erhöhen die Benutzerzufriedenheit.
Weiterlesen | Die Macht der KI im Kundenservice
Finanzbuchhaltung
RAG unterstützt Analysten durch die Bereitstellung von Echtzeit-Updates zu Marktbedingungen, regulatorischen Änderungen und Kennzahlen zur Portfolio-Leistung. Dadurch können sie in volatilen Märkten strategischer reagieren.
Content-Erstellung
Von der Zusammenfassung umfangreicher Dokumente bis zur Erstellung faktenbasierter Berichte: RAG ermöglicht eine effiziente und präzise Inhaltserstellung, sodass sich Teams auf höherwertige Aufgaben konzentrieren können.
Mitarbeiterunterstützung
Enterprise-RAG-Systeme unterstützen die Mitarbeiter bei der Beantwortung von HR-Fragen, der Einhaltung von Compliance-Richtlinien und der Bereitstellung von Schulungsmaterialien. Dies schafft eine autarke Belegschaft und reduziert den administrativen Aufwand.
Bewältigung der Herausforderungen von RAG
RAG eröffnet zwar neue Möglichkeiten, bringt aber auch Herausforderungen mit sich, deren Bewältigung gezielte Strategien erfordert:
Datenzuverlässigkeit
Die Auswahl maßgeblicher Wissensquellen ist entscheidend. Daten von minderer Qualität können den Nutzen und die Zuverlässigkeit von Antworten erheblich mindern.
Integrationskomplexität
Die Implementierung von RAG-Systemen erfordert häufig Fachwissen in den Bereichen maschinelles Lernen, semantische Suche und Prompt Engineering, insbesondere bei groß angelegten Implementierungen.
Echtzeit-Aktualisierungen
Die Pflege aktueller Wissensdatenbanken und das Einbetten von Vektoren sind unerlässlich, um sicherzustellen, dass die Antworten stets korrekt sind und die neuesten Informationen widerspiegeln.
Eindämmung von Halluzinationen
RAG reduziert Fälle von „Halluzinationen“ der KI (falsche oder erfundene Fakten) und gewährleistet, dass die Genauigkeit während der Generierungsphase ein kontinuierlicher Optimierungsbereich bleibt. Dies geschieht durch die Implementierung von Leitplanken, um mehr Vorurteile und themenfremde Informationen zu beseitigen und potenzielle Toxizität zu mindern.
Gewinnen Sie wichtige Erkenntnisse mit Hyland Knowledge Discovery
Knowledge Discovery verändert die Art und Weise, wie Sie auf Unternehmensinformationen zugreifen und diese nutzen. Dank KI-gestützter Suche und Abfragen in natürlicher Sprache sind Sie in der Lage, wichtige Daten schnell zu finden und zu überprüfen, wodurch die Suchzeit minimiert wird und Sie schneller fundierte Entscheidungen treffen können.
Hauptmerkmale
KI-gestützte Suche: Rufen Sie mit erweiterten Suchfunktionen Inforationen ab.
Benutzerdefinierte KI-Agenten: Mithilfe einer intuitiven Point-and-Click-Oberfläche erstellen Sie KI-Agenten, die auf spezifische Wissensdatenbanken spezialisiert sind, wiederkehrende Suchabfragen bearbeiten und geschäftliche Anforderungen erfüllen. Mit erweiterten LLM-Anweisungen und voreingestellten Optionen für Ton und Länge können Sie die Agenten dann individuell anpassen.
Konsolidierte Wissensansicht: Greifen Sie plattformübergreifend auf Daten zu und analysieren Sie diese, um eine nahtlose 360-Grad-Sicht auf Ihre Unternehmensinhalte zu erhalten.
Zuverlässige Validierung: Überprüfen Sie im Handumdrehen die Quellen hinter KI-generierten Antworten – samt direkten Links zu den Originaldokumenten für zusätzliche Transparenz.
Intelligentere Entscheidungsunterstützung: Aggregieren Sie Erkenntnisse aus mehreren Quellen, um die Entscheidungsfindung zu rationalisieren.
Starten Sie Ihre Transformation
Beseitigen Sie Silos, beschleunigen Sie Arbeitsabläufe und treffen Sie intelligentere Entscheidungen mit Knowledge Discovery. Finden Sie heraus Sie, wie unsere Lösungen Ihr Unternehmen noch heute revolutionieren können.

Article
Entdecken Sie die Leistungsfähigkeit von KI-Agenten
KI-Agenten revolutionieren die Art und Weise, wie wir arbeiten. Diese intelligenten digitalen Arbeitskräfte automatisieren Aufgaben, verbessern die Effizienz und erschließen neue Möglichkeiten.

Article
Die Vor- und Nachteile unstrukturierter Daten abwägen
Geben Sie eine kurze Zusammenfassung des Seiteninhalts an (Seite für Suchergebnisse).

Article
Optimieren Sie Ihre Inhalte mit künstlicher Intelligenz
Erhalten Sie die Grundlagen über die Möglichkeiten, künstliche Intelligenz in Ihre Content-Management-Strategie zu integrieren.