
リトリーバル・オーグメンテッド・ジェネレーション(RAG)とは何ですか?
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)の言語理解能力と、リアルタイムの外部データ検索を組み合わせたAI手法です。このアプローチにより、最新かつ信頼できる情報源に基づいて回答を生成できるため、AIが生み出す応答の正確性、関連性、文脈理解が大幅に向上します。

ホワイトペーパー:コンテンツインテリジェンスとAIを活用してビジネス価値を最大化する
アナリスト企業Intelligent Business Strategiesが、データの隠れた価値を引き出すのにHylandがどう役立つかを解説
AIを活用すれば、非構造化データの管理における課題を克服し、それを有用なインサイトへと変えることができます。アナリスト企業Intelligent Business Solutionsによる画期的なホワイトペーパーを通じて、コンテンツ管理の最新イノベーションをご確認ください。今すぐホワイトペーパーをダウンロードし、Hylandと共に断片化されたデータを戦略的優位性へと変革する第一歩を踏み出しましょう。
RAGと従来のLLMの違い
従来のLLMは静的な学習データのみに依存しているため、古い情報や不正確な出力を生む可能性があります。RAGは外部のナレッジベースから関連情報を動的に取得することで、この制約を克服し、一貫性があり、根拠に基づいた信頼できる応答を実現します。モダンな企業のニーズに応えるべく設計されたRAGは、AIを活用してより確実なビジネス成果をもたらします。
RAGの動作原理
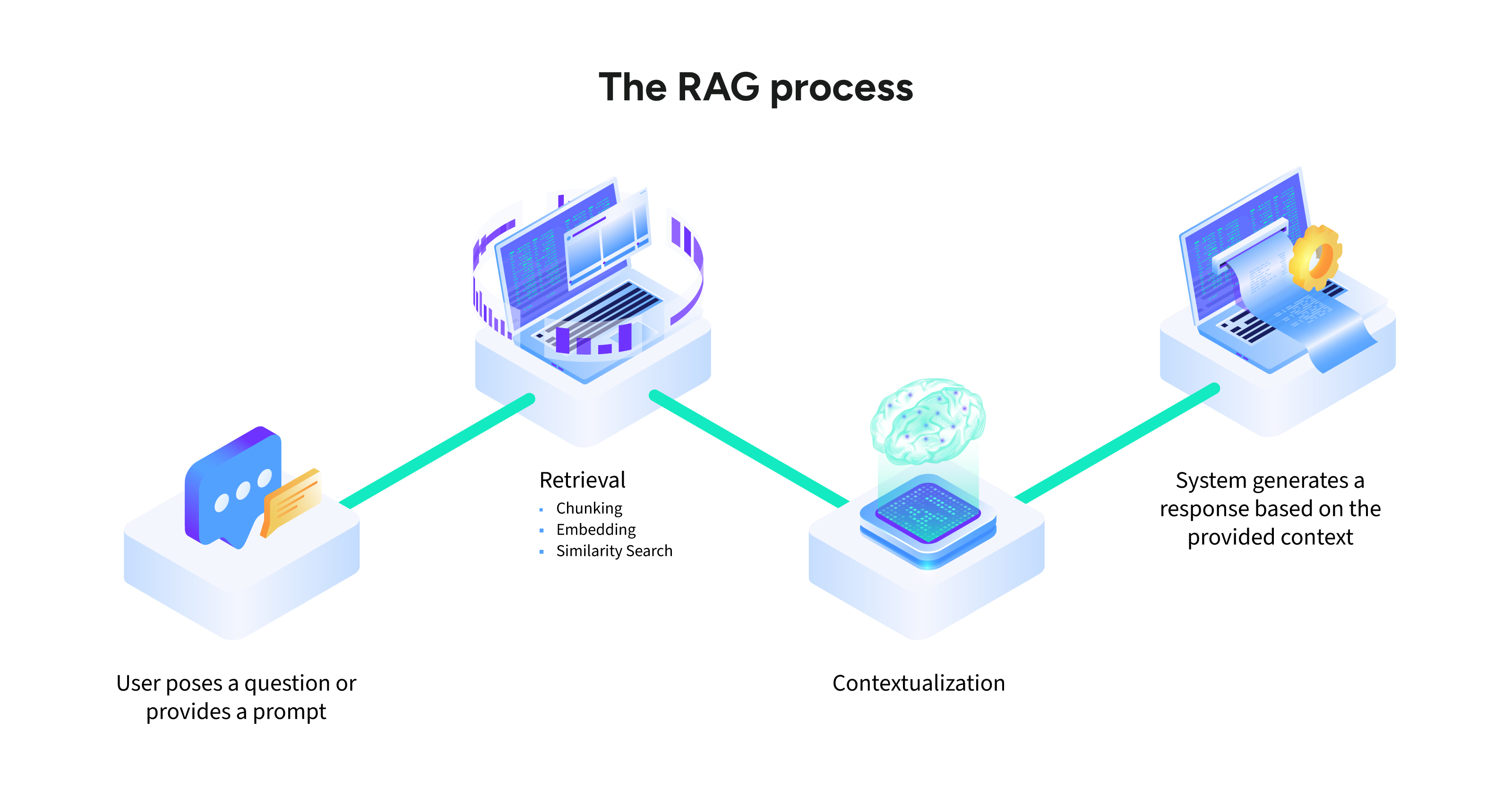
RAGは体系的なプロセスに基づいて動作し、生成モデルが詳細で正確かつ根拠に基づいた応答を提供できるようにします。以下は、RAGフレームワークにおける主要なステップです。
クエリ処理
このプロセスは、ユーザーがクエリやプロンプトを入力するところから始まります。この入力は解析され、テキストを数値的に表現した機械可読の埋め込みに変換されます。
情報検索
システムは、データベースやAPI、ドキュメントリポジトリといった外部ソースから関連情報を特定して取得します。このステップには次の内容が含まれます:
**チャンク化:**大規模な文書を小さく管理しやすい単位に分割すること。
**埋め込みマッチング:**ユーザーのクエリと比較するために、テキストチャンクを数値の埋め込みに変換します。
関連性ランキング: セマンティック検索などのアルゴリズムを用いて、最もコンテキストに適したデータを優先します。
文脈化
外部ソースから取得した関連データは元のクエリに追加され、包括的で拡張されたプロンプトが生成されます。これにより、LLMは十分なコンテキストをもとに応答を生成できるようになります。
応答生成
LLMは、取得したデータと事前学習済みの知識の両方を取り入れて強化されたプロンプトを処理し、応答を生成します。このバランスの取れたアプローチにより、出力は具体的で正確かつ関連性の高いものになります。
最終配信
生成された応答はユーザーに提示され、利用された情報源への参照やリンクが添えられることもあります。こうした透明性により信頼性が高まり、ユーザーはより深いインサイトを得ることができます。
RAGを支えるツールと技術
堅牢なRAGシステムを構築するには、次のような高度なツールや技術が必要です。
ベクターデータベース: Hyland Content Innovation Cloudのように、セマンティックな類似性に基づく検索データをサポートし、検索プロセスを加速させるプラットフォーム。
Dense retrievalモデル: Dense Passage Retrieval(DPR)などの高度な検索アルゴリズムを用いて、特定のクエリに最も関連性の高い情報を特定します。
開発フレームワーク: LangChainのようなオープンソースのフレームワークは、LLM、検索システム、埋め込みモデルを統合し、RAGを活用したアプリケーションの開発を効率化します。
ハードウェアの最適化: オンプレミスでRAGを利用する場合には、高性能なハードウェアが必要です。たとえば、NVIDIAのAIアクセラレータチップのようなハードウェアは、RAGシステムにおける効率的かつ大規模な処理を実現します。一方、LLMプロバイダーを利用する場合は、ハードウェア要件をほとんど、あるいはまったく必要としない可能性があります。
これらのツールを活用すると、組織はリアルタイムかつコンテキストを考慮した結果を提供する拡張可能なソリューションを実装できるようになります。

RAGの利点
RAGには、企業や組織における有効性を高めるいくつかの利点があります。
精度の向上
検証済みの外部知識に基づいてLLMの応答をグラウンディングすることで、事実の一貫性が高まり、誤情報を減らすことができます。
リアルタイムの関連性
RAGは、最新かつ実世界の情報へのアクセスを可能にし、古いLLMの学習データによって生じる停滞を回避します。
コスト効率
従来のAIモデルの再学習プロセスとは異なり、RAGは高額なファインチューニングを行うことなく、最新かつ関連性の高い情報を動的に取り込みます。
業種特化の応答精度
RAGは業界固有のナレッジベースとのカスタム統合に対応しており、ヘルスケア、金融、法務といった専門分野に特化した正確で信頼性の高い出力を実現します。RAGがLLMに大きな強みのひとつは、LLMが学習していないプライベートリポジトリから知識を取得できる点にあります。これにより、応答の精度がより高まります。
RAGの実際の活用例
RAGの柔軟性は、さまざまな業界やユースケースにおいて極めて高い価値を発揮します。以下に例をいくつかご紹介します:
お客様サポート
RAGを活用したAIチャットボットは、社内ポリシーやFAQ、ケースごとのデータを基に、高度にパーソナライズされた回答を提供します。これにより、待ち時間を短縮し、ユーザー満足度を高めることができます。
さらに詳しく | お客様サービスにおけるAIの力
金融
RAGは、市場動向や規制変更、ポートフォリオのパフォーマンス指標に関する最新情報をリアルタイムで提供し、アナリストを支援します。これにより、変動の激しい市場においても、より戦略的に対応することが可能になります。
コンテンツ作成
長文の文書を要約することから事実に基づいたレポートを作成することまで、RAGは効率的かつ正確なコンテンツ生成を支援し、チームがより高度な業務に集中できるようにします。
従業員のエンパワーメント
エンタープライズ向けRAGシステムは、人事関連の質問への回答、コンプライアンスガイドライン、研修資料などをスタッフが参照できるようにします。これにより、自律的に業務を遂行できる人材を育成し、管理業務の負担を軽減できるようになります。
RAGの課題への対応
RAGは新たな可能性を切り開く一方で、克服するために慎重な戦略を必要とする課題も伴います。
データの信頼性
信頼できるナレッジソースを選定することは極めて重要です。質の低いデータは、応答の有用性と信頼性を大きく損なう可能性があります。
統合の複雑性
RAG システムを実装するには、特に大規模な導入において、機械学習、セマンティック検索、プロンプトエンジニアリングの専門知識が必要です。
リアルタイムの更新
常に正確で最新の情報を反映した応答を実現するためには、最新のナレッジベースと埋め込みベクトルを維持することが不可欠です。
ハルシネーションの軽減
RAGは、AIが誤った情報や事実をでっち上げる「幻覚」を減らし、生成段階での正確性を確保する取り組みを最適化し続けています。これを実現するために、RAGはバイアスや無関係な情報を排除し、不適切な表現を軽減するためのガードレールを導入しています。
Hyland Knowledge Discoveryで重要なインサイトを引き出しましょう
Knowledge Discoveryは、企業情報へのアクセスと活用方法を革新します。AIを活用した検索や自然言語でのクエリにより、重要なデータをすばやく見つけて確認でき、検索にかかる時間を最小限に抑え、迅速かつ的確な意思決定を可能にします。
主な特長
AI搭載検索: 詳細検索機能で情報を取得します。
**カスタム AI エージェント:**直感的なポイント・アンド・クリックインターフェースを使用して、特定の知識ベースに特化したAIエージェントを構築し、反復的なクエリを処理し、ビジネスニーズに対応します。高度なLLMの指示とトーンや長さの事前設定オプションを用いてエージェントを調整します。
統合ナレッジビュー: 複数のプラットフォームにまたがるデータにアクセスして分析し、エンタープライズコンテンツをシームレスかつ360度の視点で把握できます。
信頼できる検証: AIが生成した回答の根拠となる情報源を、元の文書への直接リンクを通じて迅速に確認でき、透明性を高めます。
スマートな意思決定支援: 複数のソースから得られたインサイトを統合し、意思決定を合理化します。
変革を始めましょう
サイロを解消し、ワークフローを加速し、Knowledge Discoveryでよりスマートな意思決定を実現しましょう。ハイランドのソリューションがどのように組織を変革できるのか、ぜひご確認ください。


