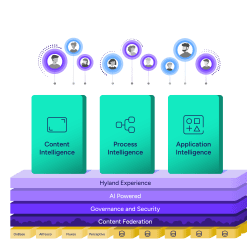
統合コンテンツ、プロセス、アプリケーションインテリジェンスプラットフォームの力を活用して、従来見過ごされてきた企業内コンテンツの価値を引き出し、スマートな新しい方法で業務を開始しましょう。
AIを活用した文書キャプチャ、分離、分類、抽出、強化で文書中心のプロセスを自動化します。
お客様独自のデジタル進化ですが、単独で向き合う必要はありません。私たちは、お客様の業界の状況と、サービスを提供する人々の固有のニーズを理解しています。
数え切れないほどのチームや部門が、ハイランドソリューションによって、経理、人事、法務部門の働き方を変えてきました。
私たちは、テクノロジーへの投資を最大化し、お客様に最高のサービスを提供できるよう、全力でサポートすることを約束します。
世界中の何千もの組織からハイランドが信頼されている理由をご覧ください。
ハイランド独自のパートナープログラムは、コンテンツサービスを通じて、より良いエクスペリエンスを創造するために、ハイランドの強みとパートナーの強みを組み合わせています。
組織のデジタルトランスフォーメーションを推進するリソースをお探しいただけます。
ハイランドは、コンテンツとシステムを連携させ、最も重要な人々とより強いつながりを築きます。
最新でオープンなクラウドネイティブプラットフォームで、強力なつながりを構築し、進化し続けることができます。
自動化戦略の価値を最大限引き出す:情報がビジネスに入り次第、すぐに開始します。
お客様のメッセージをお受け取りしました。まもなくご連絡いたします。